DGIST 로봇및기계전자공학과 박상현 교수팀이 미국 스탠퍼드 대학팀과 협력해 개인정보 및 데이터 공유 없이도 대규모 모델 학습이 가능한 연합학습 AI 기술을 개발했다.
의료 분야에서 딥러닝 모델을 학습할 경우 데이터에 환자의 개인정보가 포함되어 있어 개인정보 침해에 대한 우려가 많았다. 이 때문에 각 병원의 데이터를 중앙 서버로 모으는 것이 힘들었고, 나아가 여러 병원에서 공동으로 사용할 수 있는 대규모 모델을 개발하기도 어려웠다.
이를 해결하기 위해 연합학습은 데이터를 중앙서버에 수집하지 않고 각 병원이나 기관에서 학습한 모델만을 수집해 중앙서버로 전송하여 학습한다. 그러나 중앙 서버로 모델을 여러 번 전송해야하는 어려움이 있다. 특히 환자 데이터를 안전하게 보관해야 하는 병원에서는 모델을 중앙 서버로 반복 전송하는 데 비용과 시간이 많이 들기 때문에, 모델 전송 횟수를 최소화해야할 필요가 있다.
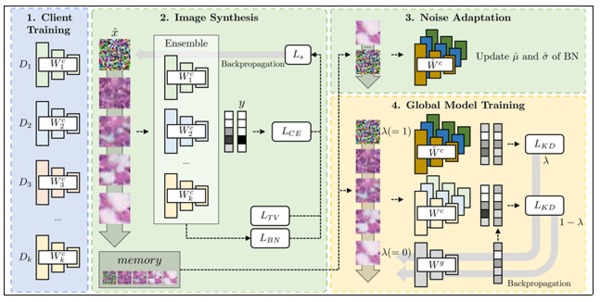
연구팀은 이미지 생성과 지식증류 기술을 활용하여 모델 전송 횟수를 최소화하면서 모델 성능을 유지하고 개선하는 방법을 개발했다. 이 방법은 기관에서 생성한 이미지와 모델을 활용하여 중앙 서버에서 모델을 학습하는 것인데, 생성된 이미지와 지식 증류를 통해 모델을 학습하는 과정을 개선했다.
연구팀은 해당 기술을 활용하여 현미경, 현미경영상, 피부경영상, OCT, 병리영상, X-ray영상, 안저영상에 대한 분류과업을 수행했다. 그 결과 기존 연합학습 기법과 비교했을 때 우수한 분류 성능을 나타내는 것을 확인했다.
박상현 교수는 “이번 연구를 통해 데이터 및 개인정보를 공유하지 않고 학습에 참여한 모든 기관에서 범용적으로 작동하는 모델을 학습할 수 있다”며, “해당 기술이 여러 의료현장에서 대규모 인공지능 모델을 개발하는 비용을 획기적으로 줄일 수 있을 것으로 기대한다”고 말했다.

대구경북과학기술원 일반사업과 한국연구재단의 신진연구지원사업을 통해 수행한 이번 연구결과는 ‘Medical Image Computing and Computer Assisted Intervention’에 게재됐다.